
Conceptele Bazelor de Date Relaţionale
Definirea bazei de date
Prin intermediul calculatoarelor electronice se pot realiza activităţi precum stocare, interogare şi administrare de colecţii de date. Prin intermediul tehnologiilor informaţionale se pot definii tehnici şi metode de oraganizare a colecţiilor de date. Organizarea în fişiere de date şi organizarea în baze de date sunt două din metodele cunoscute. Prin anii 1960 se folosea organizarea datelor în fişiere de date, dar această metodă are şi unele neajunsuri şi limitări din care se poate menţiona urmatoarele:
Datele sunt dependente de program, deci trebuie să se facă descrierea datelor în fiecare program în care sunt utilizate
Există redundanţe ridicate în cadrul colecţiilor de date
Performanţe scăzute în procesarea datelor
Pentru a se limita aceste neajunsuri şi limitări ale datelor organizate în fişiere de date au fost dezvoltate alte metode de organizare a datelor şi anume organizarea datelor în baze de date.
Definiţie: O bază de date este o colecție de informații care este organizată în așa fel încât să poată fi ușor de accesat, gestionat și actualizat.
Diferenţa între metoda de organizare a datelor în fişiere de date şi cea de organizare a datelor în baze de date este că în cea din urmă (organizarea datelor în baze de date) exiată un fişier de descriere generală a bazei, iar în acest fel se poate realiza independenţa programelor faţă de date. Acest fişier care face o descriere generală (globală) a bazei se numeşte dicţionar de date. Ca atare modificarea datelor sau extragerea acestora se face prin intermediul acestui dicţionar de date în care găsim informaţii referitoare la structura datelor.
De multe ori termenul de “bază de date” este înţeles şi utilizat greşit şi se confundă cu softul de baze de date care se utilizează. De fapt softul pentru baze de date se numeşte sistem de gestiune al bazelor de date (SGBD), iar baza de date este containierul (daca putem sa facem o analogie ca să întelegem mai bine diferenta dintre o bază de date şi un SGBD) care conţine informaţiile, iar acest containier este creat şi gestionat prin intermediul SGBD. Nu orice colecţie de date este o bază de date. Proiectarea unei baze de date înseamna să îi stabilim structura, caracteristicile, elementele componente acesteia, precum şi restricţiile care trebuie respectate şi relaţiile dintre ele.
A construi o bază de date înseamnă să introducem datele noastre în baza de date dupa ce am proiectat-o. A administra o bază de date înseamnă să asigurăm accesul utilizatorilor la date în funcţie de drepturile pe care le-am acordat fiecaruia. A interoga o bază de date înseamnă a extrage şi vizualiza acele date care îndeplinesc anumite condiţii dupa care am facut căutarea. După cum spuneam nu orice colecţie de date este o bază de date, de exemplu lista filmelor unui magazin care are ca activitate închirierea de filme clienţilor nu este o bază de date, ci este doar un simplu tabel sau o listă. Deci o bază de date diferă de un simplu tabel şi trebuie să aibă anumite proprietăţi cum ar fi:
Este o colecţie de date coerentă din punct de vedere al logicii
Este proiectată, construită şi administrată având un scop bine determinat
Reprezintă anumite aspecte ale lumii reale
O bază de date poate fi înţeleasă ca o colecţie de fişiere asociate. Modul în care aceste fişiere sunt asociate depinde de modelul utilizat. Primele modele au inclus modelul ierarhic (caz în care fişierele sunt asociate într-un mod părinte / copil, cu fiecare fişier copil având cel mult un fişier părinte), precum şi modelul de reţea ( caz în care fisierele sunt asociate ca proprietari şi membrii, similar cu modelul de reţea, cu excepţia că fiecare fişier membru poate avea mai mult de un proprietar).
Să luăm exemplu următoarele două tabele:
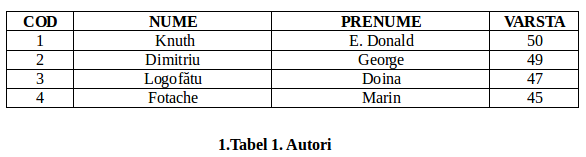
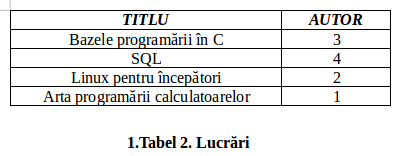
Aceste două tabele sunt legate printr-o relaţie de referinţă, câmpul „COD” din tabelul „Autori” şi câmpul „AUTOR” din tabelul „Lucrări”. Putem vedea cine a scris lucrarea „Linux pentru începatori” urmând relaţia de referintă, din care reiese că autorul este „2” din tabelul „Lucrări” adică Dumitru George din tabelul „Autori”.
O bază de date relaţională este un sistem în care datele sunt stocate în tabele de rânduri (înregistrări) şi coloane (câmpuri). Caracteristica definitorie a unei baze de date relaţională este faptul că un set complet de date este divizat în mai multe tabele (fiecare reprezentând un singur subiect) şi relaţiile pot fi stabilite între aceste tabele prin utilizarea de domenii cheie.
Structured Query Language (SQL) este folosit într-un SGBD pentru a manipula datele din tabele. Există mai multe pachete software de SGBD pe care putem să le alegem. În domeniul comercial, Oracle a fost mult timp cel mai popular SGBD, urmat de IBM DB2 şi Microsoft SQL Server. În domeniul open-source, MySQL şi PostgreSQL sunt cele mai importante SGBD. Microsoft Access este un pachet relativ ieftin, care este cel mai potrivit pentru seturi mici de date.
În 1970, atunci când E.F. Codd a dezvoltat modelul, acesta a fost considerat a fi nepractic, deoarece maşinile din acea perioadă nu puteau face faţă cerinţelor hardware necesare. Desigur, de atunci hardware-ul a făcut progrese uriaşe, astfel încât astăzi chiar şi cele mai modeste PC-uri pot rula sisteme sofisticate de SGBD. Odată cu aceasta a fost dezvoltat şi limbajul SQL. SQL este relativ usor de învăţat şi permite oamenilor să înveţe rapid cum să efectueze interogări pe o bază de date relaţională.
O înţelegere a bazelor de date relaţionale necesită o înţelegere a unora dintre termenii de bază. Datele sunt valorile stocate în baza de date. Ca atare, datele înseamnă foarte puţin. “12345” este un exemplu Informaţiile sunt date care sunt prelucrate pentru a avea un sens. De exemplu, “637500”, este populaţia oraşului Brasov.
O bază de date este o colecţie de tabele. Fiecare tabel conţine înregistrări, care sunt rândurile orizontale din tabel. Acestea sunt, de asemenea, numite tupluri. Fiecare înregistrare conţine câmpuri, care sunt coloanele verticale ale tabelului. Acestea sunt, de asemenea, numite atribute. Câmpurile pot fi de mai multe tipuri diferite. Există mai multe tipuri de date standard, iar fiecare SGBD (sistem de management de baze de date, cum ar fi Oracle sau MySQL) au de asemenea, propriile tipuri specifice de date, dar în general, acestea se încadrează în cel puţin trei tipuri, caracter, numeric şi data.
Domeniul se referă la valorile posibile pentru fiecare câmp. De exemplu, un câmp denumit “gen” poate fi limitat la valorile “masculin” si “feminin”.
Un câmp conţine o valoare „NULL” atunci când câmpul nu conţine nimic, adica o valoare necunoscută de exemplu. Câmpurile pot crea complexităţi în calcule şi au consecinţe pentru exactitatea datelor. Din acest motiv, multe câmpuri sunt în mod special setate să nu conţină valori „NULL”.
O cheie este o modalitate logică de a accesa o înregistrare într-un tabel. De exemplu, într-un tabel numit „AUTORİ”, câmpul „COD” ar putea să ne permită să identificăm unic o înregistrare. O cheie care identifică în mod unic o înregistrare se numeşte cheie primară.
Un index este un mecanism fizic care îmbunătăţeste performanţa unei baze de date. Indexurile sunt adesea confundate cu chei. Cu toate acestea, strict vorbind ei sunt parte a structurii fizice, în timp ce cheile sunt parte a structurii logice. O vizualizare este un tabel virtual alcătuit dintr-un subset de tabele reale (concrete).
O relaţie unu-la-unu (1:1) în cazul în care are loc relaţia, pentru fiecare instanţă a tabelului A, numai o instanţă din tabelul B există, si vice-versa.
O relaţie unu-la-mai-mulţi (1: m) în cazul în care relaţia există, pentru fiecare instanţă a tabelului A, mai multe instanţe a tabelului B există, dar pentru fiecare instanţă din tabelul B, numai o singură instanţă a tabelului A există.
O relaţie mulţi pentru mulţi (m: n) în cazul în care are loc relaţia, pentru fiecare instanţă a tabelului A, există mai multe instante a tabelului B, iar pentru fiecare instanţă a tabelului B, există mai multe instante ale tabelului A.
O relaţie este opţională în cazul în care, pentru fiecare instanţă a tabelului A, pot exista instanţe ale tabelului B
İntegritatea datelor descrie acurateţea, validitatea şi coerenţa datelor. Un exemplu de integritate slabă ar fi în cazul în care numele unui autor este stocat în mod diferit în două locuri diferite.
Normalizarea bazei de date este o tehnică care ne ajută la reducerea apariţiei anomaliilor de date şi slaba integritate a datelor.
Modelul relaţional constă din următoarele:
O colecţie de obiecte sau relaţii
Un set de operatori care acţionează asupra relaţiilor
İntegritate a datelor pentru acurateţe şi consecvenţă
Componente ale modelului relaţional:
Colecţii de obiecte sau relaţii care stochează datele
Un set de operatori care pot acţiona asupra relaţiilor pentru a produce alte relaţii
İntegritatea datelor pentru acurateţe şi consecvenţăO bază de date relaţională este o colecţie de relaţii sau tabele bidimensionale utilizate pentru a stoca informaţii.
De exemplu, putem avea nevoie să stocam informaţii despre toţi angajaţii dintr-o anumită companie. Într-o bază de date relaţională, putem crea mai multe tabele pentru a stoca diferite bucăţi de informaţii despre angajaţi cum ar fi un tabel cu toţi angajaţii, un tabel cu angajaţii dintr-un anumit departament precum şi un tabel cu salariul fiecarui angajat dintr-un anumit departament.
Proprietăţile bazelor de date relaţionale.
O bază de date relatională:
Poate fi accesată şi modificată executând instrucţiuni ale limbajului Structured Query Language (SQL)
Conţine o colecţie de tabele fără indicii fizice
Utilizează un set de operatoriÎn baza de date relaţională, nu e necesar să specificăm calea de acces la tabele, nici nu trebuie să ştim modul în care datele sunt aranjate fizic. Pentru a accesa baza de date, executam pur şi simplu o interogare a limbajului SQL, care este conform American National Standard Institute (ANSI) limbajul standard pentru baze de date relaţionale. Limbajul conţine un set larg de operatori pentru partiţionare şi combinarea relaţiilor. Bazele de date pot fi modificate cu ajutorul declaraţiilor SQL.
Limbajul de interogare structurat SQL ne permite să comunicăm cu serverul şi are urmatoarele avantaje:
Eficienţă
Uşor de învăţat şi folosit
Funcţionalitate completă (SQL ne permite să definim, regăsim şi să manipulăm datele în tabele)Entitate
O entitate poate să fie un obiect din lumea înconjurătoare care are o existenţă fizică, sau mai poate fi un obiect care are o existenţă abstractă, conceptuală. O entitate poate să fie dependentă (slabă) şi în acest caz depinde de alte entităţi, sau independentă adică (tare) şi atunci nu mai depinde de alte entităţi.
Observatii:
Entitaţile sunt tabele în modelele de date relaţionale
Entitaţile se scriu cu litere mari
Sunt substantive, dar nu orice substantiv este o entitate
Prin intermediul cheii primare identificam unic o entitate,cheia primară trebuie să fie unică
Este nevoie de o descriere detaliată a fiecarei entitaţi
Nu putem avea doua entitaţi cu acelaşi nume într-o diagramă, sau să avem nume diferite pentru aceeaşi entitateRelatie
Când proiectam o bază de date, modelăm un sistem care există în lumea reală, acesta descrie mai multe entități care au anumite caracteristici, sau atribute și de asemenea există anumite reguli şi legături între aceste entități. O relație descrie modul în care entitățile sunt legate una de alta. Relațiile pot fi considerate verbe care leagă două sau mai multe substantive.
Relații unu-la-unu: În acest tip de relație, fiecare instanță a unei entități se referă la o singură instanță a unei alte entități. Deci, există un raport de unu-la-unu one-to-one (1:1).
Relații unu-la-mai-mulți: În acest tip de relație, fiecare instanță a unei entități se referă la una sau mai multe instanțe ale unei alte entități. De exemplu, un autor ar fi scris mai multe cărți, dar anumite cărți au un singur autor. Acesta este cel mai comun tip de relație modelat în baze de date relaționale one-to-many (1:n).
Relații mulți-la-mai-mulți: În acest tip de relație, mai multe instanțe ale unei anumite entitaţi se referă la una sau mai multe instanțe ale unei alte entități. De exemplu, co-autorii ar putea scrie o serie de cărți many-to-many (m:n).
Observatii:
În modelul relaţional, relaţiile devin tabele speciale sau coloane care referă chei primare.
Se face o descriere pentru fiecare relaţie.
Putem avea relaţii diferite cu acelaşi nume în aceeaşi diagramă, dar în acest caz, acestea sunt diferenţiate de entităţile care sunt asociate prin relaţia respectivă
Trebuie să stabilim cardinalitatea pentru fiecare relaţie (maximă şi minimă), adică numărul de înregistrari ce aparţin relaţiei.Atributul
Este o proprietate care descrie o relaţie sau o entitate. De exemplu numele unui film este atribut al entităţii FILM_STOC, iar preţul de închiriere a unui film este un atribut al relaţiei “închiriază” ce leaga entitaţile FILM_STOC şi FILME_INCHIRIATE.
Atributele pot să fie simple (ex. pretul cu care este închiriat un film), compuse (ex. mai multe nr. de telefon a persoanei care a închiriat un film), sau derivate (ex. anul naşterii unei persoane care se obţine scăzând din anul curent vârsta persoanei respective).
Trebuie totuşi să facem diferenţa între un atribut care poate să devină coloană într-un model relaţional şi valoarea acestuia care este o valoare în coloană. Fiecarui atribut este necesar să îi atribuim o descriere, iar pentru fiecare atribut trebuie să specificam numele, tipul de date ( integer, float, char, etc) valori posibile pe care le poate lua, valori implicite, constrângeri, tipuri compuse, reguli de validare.
Diagrama E/R – Cardinalitate
Definiţie: Se numeste relaţie între entitaţile E1, E2,…Ek orice submultime a produsului cartezian al mulţimilor elementelor celor k entitaţi, adica mulţimi de elemente de forma (e1, e2,…,ek) unde “ei” este un element din “Ei”, oricare ar fi i = 1,…,k.
Prin intermediul diagramelor entitate relaţie este reprezentat grafic modelul logic al unei baze de date. Diagrama este utilizată des pentru a reprezenta grafic modelul relaţional. După cum îi spune şi numele, modelul E/R se ocupa de entitaţi, proprietaţiile sau atributele ce definesc anumite laturi ale entitaţilor şi legaturile dintre entitaţi.
Identificam entitaţile
Identificam relaţile dintre entitaţi
Stabilim cardinalităţile
Identificam atributele pentru fiecare entitate
Stabilim cheieleForme normale
Avantajele normalizarii sunt:
Mai puţin spaţiu de stocare
Actualizări mai rapide
Mai puţină neconcordanţă a datelor
Relaţii clare între date
Mai uşor de adăugat date
Structură mai flexibilă
Prima formă normală (FN1)
FN1 este adesea numita şi regulă atomică. “Atom” vine de la un cuvânt grecesc care înseamnă, în esenţă, piesa cea mai mică posibilă dintr-un obiect. Într-o bază de date, acest lucru înseamnă că fiecare coloană ar trebui să fie proiectată exclusiv să deţină numai o bucată de informaţie.
1. Înlocuim în relaţie atributele compuse cu componentele acestora.
2. Creăm o nouă relaţie pentru fiecare din grupurile repetitive.
3. În fiecare relaţie pe care am creat-o la pasul 2 introducem în schemă cheia primară a relaţiei din care am extras atributul repetitiv.
4. Stabilim cheia primară pentru fiecare relaţie pe care am creat-o la pasul 2 care este alcatuită din cheia pe care am introdus-o la pasul 3, precum şi din alte atribute a noii relaţii.Să luăm în considerare următorul exemplu şi să vedem cum aducem un tabel nenormalizat în prima formă normală (FN1).
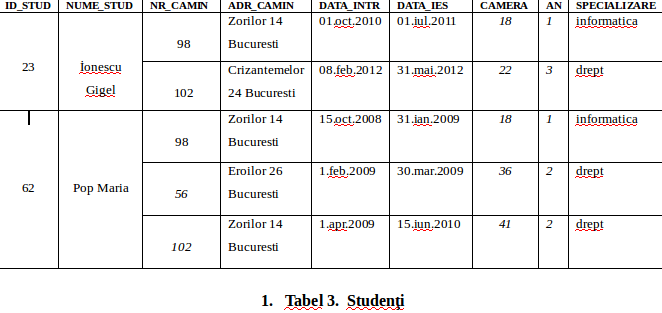
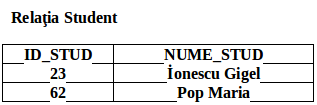
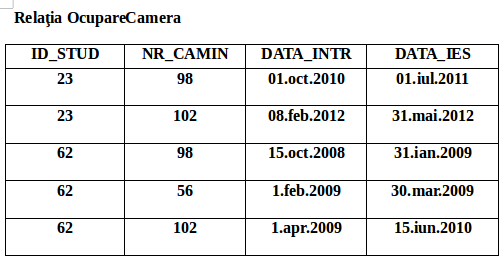
Tabelul 3 este un tabel nenormalizat. Atributul cheie este “ID_STUD”. İdentificăm grupurile repetitive care sunt de fapt detaliile despre camerele de camin pe care le ocupa studentii, anul şi specializarea.
Putem vedea ca avem valori multiple la intersecţia anumitor rânduri cu coloane. De exemplu se poate vedea în tabelul 3 ca avem două valori ale atributului “NR_CAMIN” (98,102) care corespund studentului İonescu Gigel. Ca să putem aduce acest tabel în forma de normalizare FN1 trebuie să ne asigurăm că avem o singură valoare la intersecţia dintre fiecare rând şi fiecare coloană. Acest lucru îl facem prin eliminarea grupului repetitiv. Deci eliminam grupul repetitiv plasând într-o relaţie separată datele respective împreună cu o copie a atributului cheie initial “ID_STUD” după care identificăm o cheie primară pentru noua noastră relatie.
Relaţia Studenţi (ID_STUD, NUME_STUD)
Relaţia CameraCamin ( ID_STUD, NR_CAMIN, ADR_CAMIN, DATA_INTR, DATA_IES, CAMERA, AN,
SPECIALIZARE)

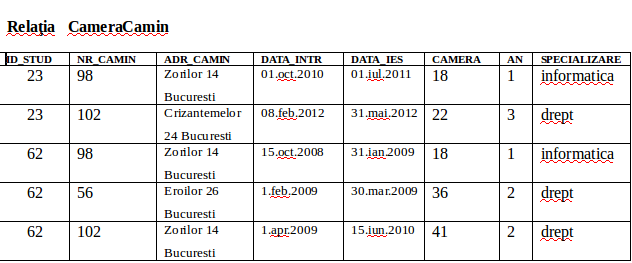
Cele două relaţii sunt acum în FN1 deoarece avem o singură valoare la intersecţia dintre fiecare rând şi fiecare coloană.
O altă modalitate de a elimina grupul repetitiv este să transformăm un rând care conţine mai multe valori ale unui atribut în mai multe randuri care să conţină o singură valoare pentru acel atribut, iar relatia care va rezulta şi pe care am denumit-o CameraCamin va fi in FN1, apoi trebuie să identificam cheile candidat ale relaţiei noastre CameraCamin care sunt de fapt chei compuse şi anume (ID_STUD, NR_CAMIN), (ID_STUD, DATA_INTR), (NR_CAMIN, DATA_INTR). Acum alegem drept cheie primară urmatoarele atribute (ID_STUD, NR_CAMIN)
CameraCamin (ID_STUD, NR_CAMIN, NUME_STUD, ADR_CAMIN, DATA_INTR, DATA_IES, CAMERA, AN, SPECIALIZARE)Această relaţie este în forma FN1 pentru că avem o singură valoare la intersecţia dintre fiecare rând şi coloană, dar totuşi relaţia noastră conţine date care se repetă de mai multe ori şi prin urmare este supusă anomaliilor de reactualizare. Ca să putem elimina această anomalie de reactualizare trebuie să transformam relaţia noastra în forma FN2.
A doua formă normala (FN2)
ID_STUD, NR_CAMIN -> DATA_INTR, DATA_IES (cheie primară)
ID_STUD -> NUME_STUD (dependenţă partială)
NR_CAMIN -> ADR_CAMIN, CAMERA, AN, SPECIALIZARE (dependenţă partială)
AN -> SPECIALIZARE (dependenţă tranzitivă)
ID_STUD , DATA_INTR -> NR_CAMIN, ADR_CAMIN, DATA_IES, CAMERA, AN, SPECIALIZARE (cheie candidat)
NR_CAMIN, DATA_INTR -> ID_STUD, NUME_STUD, DATA_IES (cheie candidat)
Atributul (NUME_STUD) este dependent parţial de cheia primară ID_STUD.
Atributele (ADR_CAMIN, CAMERA, AN, SPECIALIZARE ) sunt parţial dependente de cheia primară, ele sunt dependente numai de atributul “NR_CAMIN”.

Student (ID_STUD, NUME_STUD)
OcupareCamera (ID_STUD, NR_CAMIN, DATA_INTR, DATA_IES )
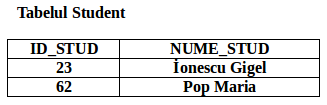
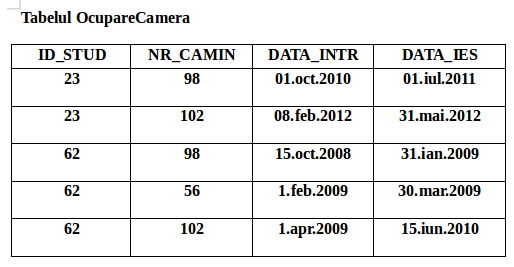
CaminStudent (NR_CAMIN, ADR_CAMIN, CAMERA, AN, SPECIALIZARE )A treia formă normală (FN3)
– dependenţele funcţionale asupra câmpurilor care nu sunt cheie sunt eliminate prin plasarea acestora într-un tabel separat. La acest nivel, toate câmpurile (coloanele) care nu sunt cheie depind de cheia primară.
– un rând este în formă normală (FN3) dacă şi numai dacă este în a doua formă normală (FN2) şi atributele care nu contribuie la o descriere a cheii primare sunt mutate într-un tabel separat.
Tabelul Student
ID_STUD -> NUME_STUD
Tabelul OcupareCamera
ID_STUD, NR_CAMIN -> DATA_INTR, DATA_IES
ID_STUD, DATA_INTR -> NR_CAMIN, DATA_IES
NR_CAMIN, DATA_INTR -> ID_STUD, DATA_IES
Tabelul CaminStudent
NR_CAMIN -> ADR_CAMIN, CAMERA, AN, SPECIALIZARE (dependenţa partială)
AN-> SPECIALIZARE (dependenţa tranzitivă)
Camin (NR_CAMIN, ADR_CAMIN, CAMERA)
Studentul (AN, SPECIALIZARE)

Student ( ID_STUD, NUME_STUD )
OcupareCamera ( ID_STUD, NR_CAMIN, DATA_INTR, DATA_IES )
Camin ( NR_CAMIN, ADR_CAMIN, CAMERA )


Reguli de integritate
Exemplu de constrângere de integritate referenţiala:
ANGAJAT( ang_id, ang_nume)
CONT( cont_id, ang_id, data_cont)
Securitatea în BD Oracle
Proiectarea securităţii
Securizarea bazei de date Oracle
1. Autentificarea
2. Controlul accesului
3. Configurarea securitaţii
4. Auditul1.Autentificarea
SQL> SELECT * FROM dba_users_with_defpwd
SQL> SELECT username, password from dba_users;
SQL> SELECT username, profile FROM dba_users;
SQL> SELECT * FROM dba_profiles;
SQL> SELECT username FROM dba_users WHERE password=’EXTERNAL’;2. Controlul accesului
SQL> SELECT * FROM dba_sys_privs;
SQL> SELECT * FROM dba_role_privs;
SQL> SELECT * FROM dba_col_privs;
SQL> SELECT * FROM dba_tab_privs;
3. Configurarea securităţii
• AUDIT_FILE_DEST
• AUDIT_SYS_OPERATIONS (Should be set to TRUE.)
• AUDIT_TRAIL (Avoid FALSE or NONE settings.)
• DIAGNOSTIC_DEST
• DISPATCHERS
• GLOBAL_NAMES (Should be set to TRUE.)
• LOG_ARCHIVE_% (Note: There are multiple parameters that exist that begin with LOG_ARCHIVE.)
• MAX_ENABLED_ROLES
• O7_DICTIONARY_ACCESSIBILITY (Should be set to FALSE.)
• OS_AUTHENT_PREFIX (Should be set to NULL, if possible. Should not be set to ops$.)
• OS_ROLES (Should be set to FALSE.)
• REMOTE_LISTENER (Should be set to NULL, unless a remote listener is needed.)
• REMOTE_LOGIN_PASSWORDFILE (Should be set to NONE, if possible.)
• REMOTE_OS_AUTHENT (Should be set to FALSE.)
• REMOTE_OS_ROLES (Should be set to FALSE.)
• RESOURCE_LIMIT (Should be set to TRUE.)
• SEC_CASE_SENSITIVE_LOGON (Should be set to TRUE.)
• SEC_MAX_FAILED_LOGIN_ATTEMPTS (Should be set to 10.)
• SEC_PROTOCOL_ERROR_FURTHER_ACTION (Avoid the setting NONE.)
• SEC_PROTOCOL_ERROR_TRACE_ACTION (Avoid the setting NONE.)
• SEC_RETURN_SERVER_RELEASE_BANNER (Should be set to FALSE.)
• SMTP_OUT_SERVER (Should list only authorized SMTP servers, if utilized.)
• SPFILE
• SQL92_SECURITY (Should be set to TRUE.)
• UTL_FILE_DIR (Should be set to a specific directory used only for necessary purposes. Values such as /tmp or * should not exist.)
• _TRACE_FILES_PUBLIC (Should be set to FALSE.)Putem aborda vulnerabilitățile de securitate pe care le-am menționat mai sus, prin aplicarea patch-urilor. Fara patch-uri corespunzătoare în vigoare, un atacator ar putea folosi vulnerabilitățile respective pentru a exploata privilegiile lor sau chiar pentru a obţine accesul.
4. Auditul
SQL> SELECT * FROM dba_stmt_audit_opts
SQL> SELECT * FROM dba_priv_audit_opts;Putem utiliza următoarea interogare pentru a determina obiectul verificat:
SQL> SELECT * FROM dba_obj_audit_opts;
Criptarea
Cifrurile bloc – de exemplu, Cipher Block Chaining (CBC)
Algoritmi cu cheie simetrică – de exemplu, AES si 3DES
Algoritmi cu cheie publică – de exemplu, rural service area (RSA)
Certificate – de exemplu, certificate X.509
Mesaje rezumate – de exemplu secure hash algorithm-1 (SHA-1) si (MD5)
Semnăturile digitale – de exemplu, semnăturile digitale RSA
Serviciile de securitate – de exemplu, SSL
Aceste elemente sunt apoi utilizate pentru următoarele scopuri (toate acestea sunt relevante în securitatea Oracle):
Confidențialitatea, cum ne putem asigura că spargătorii de coduri sau un hoţ care sustrage datele wireless nu le poate citi?
İntegritatea mesajului, cum putem şti că un mesaj nu a fost falsificat şi modificat înainte de a ajunge în baza de date?
Autentificarea – cum putem şti că un mesaj sau o acțiune vine de la o anumită persoană sau organizaţie?Criptare, algoritmi de criptare, şi cifruri
Există mulţi algoritmi de cheie simetrică (sau cifruri). Toate aceste cifruri funcționează în acelasi mod în ceea ce priveste faptul că o cheie de criptare se utilizează pentru criptarea textului clar pentru a forma un text cifrat şi apoi aceeaşi cheie este utilizată pentru a decripta textul cifrat în text clar. Există mai multe cifruri pe care le putem alege. Atunci când utilizam criptarea în cadrul Oracle vom putea alege unul din aceste cifruri:
DES-DES este un algoritm pe care nu ar trebui să-l folosim niciodată. DES a fost ales ca standardul oficial american în 1976, când computerele erau mult mai slabe în ceea ce priveste puterea de procesare. Algoritmul a fost întotdeauna controversat, are o lungime scurtă a cheii de 56 de biți, şi pentru că părțile din el sunt clasificate, s-a crezut întotdeauna că US National Security Agency (NSA) a menținut o cale de acces spre acest algoritm. Cu calculatoare de astăzi se poate sparge DES în aproximativ 24 de ore, deci e bine să nu-l utilizăm niciodată.
3DES – triplu DES este un algoritm care a fost în uz pe scară largă şi este încă – în special în sectorul financiar. Acesta este considerat a fi un algoritm puternic, dar există algoritmi mai buni in ziua de azi pe care îi putem alege. DES este prea slab din cauza cheii sale scurte de 56 biti, astfel 3DES a evoluat ca o modalitate simplă de a consolida criptarea împotriva atacului de tip „brute force”. Există două variante. In prima variantă, numită EEE, sunt făcute trei etape de criptare. În a doua variantă, numită EDE, primul pas şi al treilea sunt pasi de criptare, dar al doilea pas este un pas de decriptare (evident, nu cu aceeaşi cheie ca primul pas). 3DES fie are o lungime de 168 biți a cheii (de trei ori 56 biți utilizati în DES) sau 112 biți în cazul în care prima şi a treia cheie DES sunt aceleaşi.
AES-AES este algoritmul pe care ar trebui să-l utilizăm întotdeauna dacă avem de ales. AES (cunoscut sub numele de Rijndael ) a fost adoptat ca standard de criptare de catre guvernul Statelor Unite în 2002, după o perioadă de cinci ani cât a durat procesul de analiză, comparație şi selecție. Acesta a fost analizat pe larg şi este utilizat pe scară largă în toată lumea. Dimensiunile cheilor sunt fie 128, 192, sau 256 biti – adică AES128, AES192, AES256 deci optiuni care pot fi selectate atunci când acestea apar în Oracle.
AES, 3DES, DES toate sunt numite cifruri bloc. Se numesc cifruri bloc, deoarece acestea funcționează întotdeauna pe un bloc de date.
Criptografie cu cheie publică
Deci criptografia cu cheie publică nu are o problemă în a distribui cheia, problemă care exista în criptografia cu chei simetrice. Dacă dorim ca un client şi serverul să comunice printr-un canal nesigur tot ce trebuie să facem este să generăm două perechi de chei publică / privată – o cheie pentru client şi una pentru server.
Cheia publică nu poate fi utilizată pentru a decripta mesajul numai cheia privată poate face acest lucru şi cheia privată nu poate fi calculată din cheia publică. Serverul primeşte mesajul şi îl decriptează folosind cheia sa privată. Daca vrea să trimită un răspuns clientului, ia mesajul şi îl criptează folosind cheia publică a clientului. Acest text criptat este trimis pe canalul nesigur şi clientul îl decriptează folosind cheia sa privată. Clientul şi serverul reuşesc să comunice fără să partajeze vreun secret.
Identificarea
Metode de identificare
Identificare furnizată de utilizator
Avantajul de a folosi identificarea furnizată de utilizator este că identificatorul (de exemplu, numele de utilizator) este, în general, flexibil. Acest lucru permite administratorilor să creeze identificatori intuitivi, care sunt usor de reamintit pentru utilizatori. De exemplu, un nume de utilizator poate fi creat pe baza primei initiale a numelui persoanei şi prenumele, dar acest beneficiu este o slăbiciune. Identificatorii, care pot fi ghiciti cu usurință pot slăbi securitatea globală.
Identificare realizată prin tehnologie
Tehnologia biometrică
Mai multe companii în prezent încearcă să aducă la maturitate diverse tehnologii biometrice. Recunoaşterea facială, scanerea irisului, geometria mâinii, şi cititoare de amprente sunt printre cele mai populare. Datele biometrice sunt ideale din multe puncte de vedere. Utilizatorii nu le pot uita, şi aceste date pot fi aproape imposibil de ghicit. Furtul părții biometrice este puțin probabilă, dar există un risc asociat cu reprezentarea digitală biometrică care poate fi furată. Confuzia referitoare la cum sunt utilizate datele biometrice este frecventă. Acest lucru se datorează faptului că datele biometrice pot fi folosite atât pentru identificare cât şi în procesele de autentificare. Cu identificarea biometrică, informaţiile biometrice sunt considerate unice şi pot fi utilizate pentru a identifica cu exactitate persoana care prezintă aceste date biometrice. Acest mod de identificare diferă de identificarea furnizată de utilizator, deoarece utilizatorul nu va spune sistemului cine este, sistemul îl identifică în mod automat. De reținut un lucru, aceasta nu este autentificare, aceasta este doar identificarea, autentificarea biometrica este procesul de comparare a semnăturii, datele biometrice, cu o referință pentru a dovedi sau infirma o identitate.
Identitatea calculatorului
Firewall-urile şi diverse tehnologii securizate de rutare sunt puternic dependente de adrese MAC şi adresele IP. Servere de aplicații şi bazele de date securitate pot utiliza, de asemenea, adresele IP pentru a ajuta la furnizarea de straturi suplimentare de securitate.
Identităţi digitale
Ne putem gândi la un certificat ca la un paşaport digitalizat. Identitățile digitale sunt bine definite, atât structural cât şi semantic, şi sunt consecvente în toate aplicațiile şi platforme care acceptă standardele certificate. Acest ultim punct este esențial pentru asigurarea interoperabilității între aplicațiile şi produsele oferite de către diferiţi furnizori. Certificatele digitale sunt populare, nu numai pentru că certificatele sunt bazate pe standarde, dar şi pentru că certificatele conțin informații suplimentare care pot fi utilizate în punerea în aplicare a controalelor de securitate eficiente. Pentru identificarea utilizatorului, certificatele digitale sunt de obicei instalate în browserele Web ale utilizatorului. Ele pot fi, de asemenea, integrate în dispozitivele fizice, cum ar fi cardurile inteligente. Pentru a securiza identitatea digitală, utilizatorul poate fi obligat să furnizeze un cod PIN sau o parolă pentru deblocarea certificatului.
Falsificarea
Retragerea certificatului, care există în aproape toate aplicațiile care acceptă certificate digitale, rezolvă utilizarea ilicită a certificatelor digitale, dar numai atunci când utilizatorul sau administratorul devine constient de faptul că furtul a avut loc.
Furtul de identitate
Deoarece o mulțime de informații care pot fi utilizate pentru a crea identități false sunt deturnate din bazele de date şi aplicații prost concepute. Alegerea necorespunzătoare a unui element de identificare ar putea fi un catalizator pentru furtul de identitate. Să ne uităm la o structură de tabel posibilă ca să vedem ce riscuri există.
CREATE TABLE CLIENTI (Nume VARCHAR2(50),
Prenume VARCHAR2(50),
Nr_identif_client VARCHAR2(11),
Zi_nastere DATE);Datele din acest tabel sunt în mod clar importante (sensibile). Protejarea accesului la datele din acest tabel este o cerință de securitate evidentă. La prima vedere nu există un risc de securitate chiar atât de evident şi din acest motiv nu este neobişnuit şi anume ca un proiectant de aplicații de baze de date să utilizeze „Nr_identif_client” ca un identificator al clientului. Acest lucru este foarte riscant şi considerat a fi o decizie foarte proastă. Motivul este faptul că identificatorii clienţilor sunt uneori necesari dezvoltatorilor de aplicații pentru testare sau depanare, sau pentru verificarea accesului la baza de date de către administratorii bazei de date.
Autentificarea
Metode de autentificare
Metodele de autentificare se încadrează în următoarele trei categorii:
Autentificare puternică, de obicei, implică faptul că autentificarea nu poate fi usor de ghicit sau falsificat. Tehnologiile de autentificare au diferite abilități pentru a îndeplini sarcinile lor de autentificare. Unul dintre criterile pentru determinarea complexitătii de autentificare este de exemplu, cât de greu este să se falsifice metoda de autentificare.
Ceva ce noi suntem şi ceva ce noi avem (posedăm) sunt considerate forme mai puternice de autentificare decât ceva ce noi stim. Parolele pot fi ghicite şi prin urmare, sunt considerate metode de autentificare slabă. Falsificarea unui certificat X.509 (ceva ce avem) sau duplicarea datelor biometrice (ceva ce avem), nu este la fel de usor de falsificat ca şi ceeia ce ştim (parolele). Prin urmare, certificatele digitale, autentificări biometrice sunt considerate metode puternice de autentificare.
Nu vreau aici să sugerez că parolele nu ar trebui să fie utilizate pentru autentificare. Putem de exemplu, în calitate de administrator de baze de date, să ne asigurăm că utilizatorii bazei de date folosesc parole puternice prin implementarea unei rutine în care se utilizează parole de complexitate mare şi un profil de parolă.
Cele mai bune practici de autentificare securizată. Criptarea autentificatorilor.
Asigurarea securității pentru stocarea autentificatorilor este la fel de importantă. Adesea, autentificatorii vor fi păstraţi într-o formă criptată pentru a păstra confidențialitatea autentificatorului.
Abrevierea (prescurtatea) autentificatorilor
Criptarea parolelor, care permite o probabilă decriptarea a acestora, ar putea obţine parolele în text clar. Pentru a rezolva acestă problemă, se poate utiliza o tehnologie numită abrevierea sau prescurtarea parolelor. Prin intermediul abrevierii textul în clar se converteşte în text indescifrabil. Spre deosebire de criptare, nu există nicio modalitate de a obţine înapoi textul în clar. Deci, nu există nici o modalitate de a lua o valoare în forma abreviată şi apoi să determinăm ce a creat această valoare. Abrevierea este numită o funcție unidirecțională din cauza acestei proprietăţi. O altă proprietate importantă a abrevierii este faptul că aceeaşi intrarea va genera întotdeauna aceeaşi ieşire. Autentificarea prin parolă are loc prin abrevierea parolei şi stocarea rezultatului într-o valoare trunchiată sau abreviată. Atunci când utilizatorul introduce o parolă pentru autentificare, valoarea autentificarii furnizate de utilizator (a parolei), va fi comparată prin intermediul procesului de autentificare cu valoarea abreviată stocată. Dacă valoarea trunchiată sau abreviată se potriveste, atunci intrarea trebuie de asemenea sa se potrivească şi prin urmare parolele sunt aceleaşi. Modalitatea de abreviere poate fi folosită pentru alți autentificatori în acelaşi mod.
Baza de date
Parolele: Parolele pot fi fie autentificate de către baza de date sau de catre Oracle LDAP
Oracle suportă autentificarea sistemului de operare şi autentificări puternice, care includ certificate PKI, Kerberos, DCE şi RADIUS. Standardul RADIUS extinde capacitățile de autentificare pentru a include elementele biometrice integrate, şi carduri inteligente.Asocierea utilizatoriilor cu schemele bazelor de date
1:1 Această schemă „unu-la-unu „ se produce în principal în programe client-server. Acest lucru înseamnă că fiecare utilizator final are un cont distinct bazei de date.
N: M Acesta schemă „totii-la-mai-multi” se întâmplă ocazional în aplicații Web. Aceasta înseamnă că toți utilizatorii finali sunt mapaţi la mai multe scheme diferite. Toți utilizatorii cu aceleaşi privilegii sunt conectaţi la aceeaşi schemă.
N: 1 Acestă schemă „toti-la-unul” este o aplicație Web tipică. Aplicația conectează toți utilizatorii finali la aceeaşi schemă a bazei de date. Schema dispune de o uniune a tuturor privilegiilor pentru toţi utilizatorii conectaţi la ea.Schema sau maparile sunt enumerate în ordine de la simplu la complex pentru a construi securitatea bazei de date. Există mai mulți factori care influențează alegerea modelului. Scalabilitatea, performanţa şi administrarea uşor de folosit ne solicită de multe ori cea mai mare atenție. Securitatea însă trebuie să fie de asemenea un aspect care trebuie avut în vedere.
Privilegiile utilizatorului pentru conturile unice în baza de date.
Partajarea unui cont privilegiat printre un grup de utilizatori este o practică proastă. În multe organizații, schimbul de conturi de utilizator este interzisă de politica de securitate, dar este totuși încă folosită şi se practica de multe ori. Dacă ceva nu merge bine în acest caz, nu vom fi în măsură să spunem care utilizator a fost conectat ca utilizator al bazei de date în momentul în care s-a întâmplat ceva. Prin urmare, nu există nicio responsabilitate a utilizatorului. Schema 1:1 face securitatea bazei de date simplă pentru că identitatea utilizatorului este întotdeauna disponibilă pentru baza de date, prin urmare, utilizatorul este responsabil.
Conturi de baze de date partajate
Modelul de schemă N: 1, conectează toți utilizatorii finali la aceeaşi schemă a bazei de date. Această schemă este întotdeauna cea mai îndoielnică în ceea ce priveste securitatea. Problema cu proiectarea este faptul că e dificil pentru baza de date să separe privilegiile de securitate pentru utilizatori diferiți, deoarece toți sunt conectaţi la aceeaşi schemă. Garantarea că numai privilegiile potrivite sunt disponibile pentru utilizator este lăsată în cea mai mare parte apliacatiei. Când proiectam şi construim aplicații, trebuie să ne asiguram că este mentinut principiul cu privilegii minime. Proprietarul datelor are toate privilegiile asupra datelor. În cazul în care utilizatorii se conectează la această schemă, chiar dacă prin intermediul aplicației noastre exista un risc semnificativ de penetrare a securităţii sistemului. Aceasta se poate întampla, în cazul în care un utilizator poate sparge aplicaţia, utilizatorul va avea control complet pe partea datelor. Din acest motiv, o practică mai bună de securitate este să ne asigurăm că utilizatorii aplicației nu se pot conecta direct la contul de date.
Un aspect important al procesului de identificare este păstrarea identității. Noi trebuie să ne asigurăm că identitățile de utilizator sunt disponibile peste tot unde securitatea le solicită.
Administratorii nu ar trebui să partajeze conturi. Schemele de partajare ar trebui să fie făcute doar atunci când identitatea utilizatorilor finali poate fi păstrată şi privilegiile bazei de date sunt identice pentru toți utilizatorii conectați la aceeaşi schemă. Înțelegerea identificării şi autentificării este importantă pentru modul în care formulăm politicile noastre de securitate. Trebuie să evaluam cu atenție cerințele de securitate, valoarea şi importanţa datelor utilizate, administrarea lor, precum şi costurile asociate cu diferite tehnologii de autentificare.
Studiul de caz
Crearea bazei de date
Pentru a crea baza de date denumită “FILM” voi utiliza aplicaţia cu interfaţă grafică Oracle Database XE 11.2. Fereasta de login este aratată în figura 9 de mai jos.
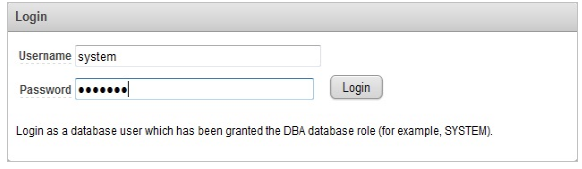
Figura 9. Fereastră login aplicaţie Oracle Database XE 11.2
După ce procesul de logare în aplicaţie a avut loc, vom fi directionaţi spre o fereastră prin intermediul căreia putem crea baza noastră de date “FILM”. În această fereastră aplicaţia ne solicită să alegem crearea unei noi baze de date sau utilizarea unei baze deja existente, numele bazei de date, în cazul nostru alegem “FILM”, numele de utilizator şi parola, apoi facem clic pe Create Workspace. Fereastra prin intermediul careia creăm baza de date “FILM” este aratată în fig.10.
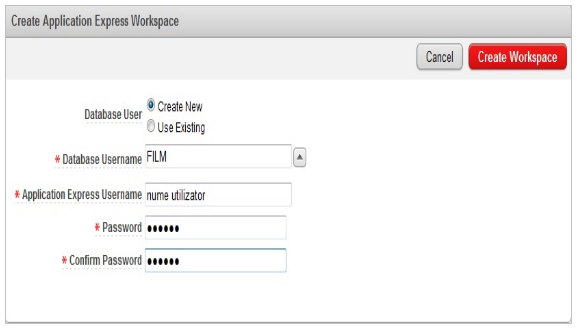
Figura 10. Fereastră creare bază de date „FILM”
După ce baza de date a fost creată avem acces la interfata grafica a aplicaţiei prin intermediul careia putem crea, insera, actualiza şi sterge tabelele şi informaţiile conţinute în baza noastra “FILM”. İnterfaţa grafică a aplicaţiei este aratată în figura 11.
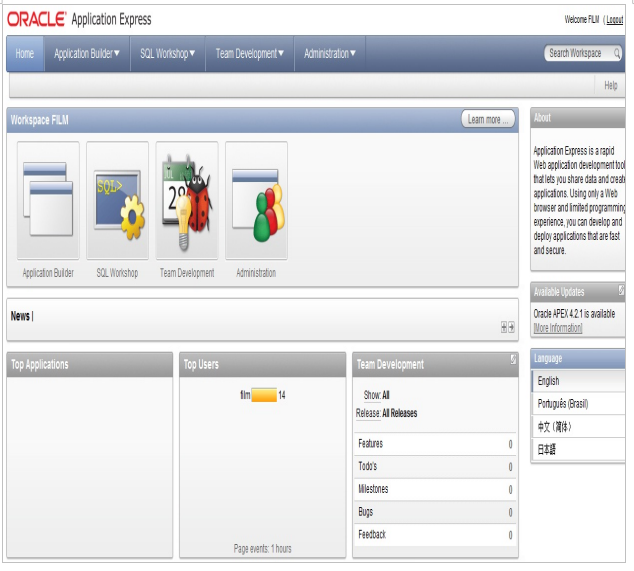
Figura 11. Interfaţa grafică aplicaţie Oracle Application Express
Tabelele bazei de date
FILM_STOC
GEN_FILM
LIMBA_FILM
SUBTITRARE
FILM_LIPSA_STOC
COPII_FILM
FILME_INCHIRIATE
CLIENTI_INCHIRIERE_FILMStructura detaliată a tabelelor este următoarea:
CREATE TABLE “FILM_STOC”
(“ID_FILM” NUMBER NOT NULL ENABLE,
“COD_GEN_FILM” VARCHAR2(10) NOT NULL ENABLE,
“NUME_FILM” VARCHAR2(50),
“PRET_VHS” NUMBER(2,0),
“PRET_DVD” NUMBER(2,0),
“AN_APARITIE” NUMBER(4,0),
CONSTRAINT “FILM_STOC_PK” PRIMARY KEY (“ID_FILM”, “COD_GEN_FILM”) ENABLE
) ;
CREATE TABLE “GEN_FILM”
(“COD_GEN_FILM” VARCHAR2(6) NOT NULL ENABLE,
“DESCRIERE_FILM” VARCHAR2(10),
CONSTRAINT “GEN_FILM_PK” PRIMARY KEY (“COD_GEN_FILM”) ENABLE
) ;
CREATE TABLE “LIMBA_FILM”
(“ID_FILM” NUMBER NOT NULL ENABLE,
“COD_LIMBA” VARCHAR2(6) NOT NULL ENABLE,
CONSTRAINT “LIMBA_FILM_PK” PRIMARY KEY (“ID_FILM”, “COD_LIMBA”) ENABLE
) ;
CREATE TABLE “SUBTITRARE”
(“COD_LIMBA” VARCHAR2(3) NOT NULL ENABLE,
“NUME_LIMBA” VARCHAR2(10) NOT NULL ENABLE,
CONSTRAINT “SUBTITRARE_PK” PRIMARY KEY (“COD_LIMBA”, “NUME_LIMBA”) ENABLE );FILM_LIPSA_STOC – tabel ce conţine informaţii despre filmele care nu sunt disponibile, are un cod unic carte identifică filmele nedisponibile, cod care este şi cheie primară a tabelului. Comanda de creare a tabelului este următoarea:
CREATE TABLE “FILM_LIPSA_STOC”
(“ID_LIPSA_FILM” NUMBER NOT NULL ENABLE,
“FILM_DENUMIRE” VARCHAR2(50),
“FORMAT_SUPORT” VARCHAR2(3),
CONSTRAINT “FILM_LIPSA_STOC_PK” PRIMARY KEY (“ID_LIPSA_FILM”) ENABLE
) ;COPII_FILM – tabel ce conţine informaţii despre filmele care au copii, cât şi numărul acestor copii. Cheia primară este una compusă din câmpurile “id_film” şi “ nr_copii”. Comanda de creare a tabelului este următoarea:
CREATE TABLE “COPII_FILM”
(“ID_FILM” NUMBER NOT NULL ENABLE,
“NR_COPII” NUMBER NOT NULL ENABLE,
“DENUMIRE_FILM” VARCHAR2(50),
“FORMAT_MEDIA” VARCHAR2(3),
CONSTRAINT “COPII_FILM_PK” PRIMARY KEY (“ID_FILM”, “NR_COPII”) ENABLE
) ;FILME_INCHIRIATE – tabel ce conţine informaţii despre filmele închiriate clienţilor. Cheia primară este o cheie compusă din campurile “ id_film” şi “id_film_copie”. Comanda de creare a tabelului este următoarea:
CREATE TABLE “FILME_INCHIRIATE”
(“ID_FILM” NUMBER,
“ID_FILM_COPIE” NUMBER,
“DATA_INCHIRIERE” DATE,
“TITLU_FILM” VARCHAR2(50),
“PRET_INCHIRIERE” NUMBER,
“PENALIZARE_INTARZIERE_PIERDERE” NUMBER,
“DATA_RETURNARE” DATE,
CONSTRAINT “FILME_INCHIRIATE_PK” PRIMARY KEY (“ID_FILM”, “ID_FILM_COPIE”) ENABLE
) ;CLIENTI_INCHIRIERE_FILM – tabel ce conţine un cod ce identifică unic fiecare client care a închiriat filme , cât şi datele personale ale acestora. Codul unic care identifică clienţii este şi cheia primară a tabelului. Comanda de creare a tabelului este următoarea:
CREATE TABLE “CLIENTI_INCHIRIERE_FILM”
(“CLIENT_ID” NUMBER,
“NUME” VARCHAR2(20),
“PRENUME” VARCHAR2(20),
“ADRESA” VARCHAR2(50),
“ORAS” VARCHAR2(16),
“CNP” VARCHAR2(13),
“TEL” VARCHAR2(10),
CONSTRAINT “CLIENTI_INCHIRIERE__FILM_PK” PRIMARY KEY (“CLIENT_ID”) ENABLE );
Inserare date în baza de date
INSERT INTO “FILM”.”FILM_STOC” (ID_FILM, COD_GEN_FILM, NUME_FILM, PRET_VHS, PRET_DVD, AN_APARITIE) VALUES (’01’, ‘act’, ‘The Matrix’, ’30’, ’18’, ‘2001’)
INSERT INTO “FILM”.”FILM_STOC” (ID_FILM, COD_GEN_FILM, NUME_FILM, PRET_VHS, PRET_DVD, AN_APARITIE) VALUES (‘4’, ‘com’, ‘You Have Got Mail’, ’35’, ’15’, ‘2007’)
INSERT INTO “FILM”.”FILM_STOC” (ID_FILM, COD_GEN_FILM, NUME_FILM, PRET_VHS, PRET_DVD, AN_APARITIE) VALUES (‘5’, ‘dra’, ‘Red Corner’, ’34’, ’15’, ‘2004’)
INSERT INTO “FILM”.”FILM_STOC” (ID_FILM, COD_GEN_FILM, NUME_FILM, PRET_VHS, PRET_DVD, AN_APARITIE) VALUES (‘6’, ‘SF’, ‘Blade Runner – Director is Cut’, ’36’, ’19’, ‘2008’)
INSERT INTO “FILM”.”FILM_STOC” (ID_FILM, COD_GEN_FILM, NUME_FILM, PRET_VHS, PRET_DVD, AN_APARITIE) VALUES (‘8’, ‘cart’, ‘A Bug is Life’, ’32’, ’14’, ‘2008’)
INSERT INTO “FILM”.”FILM_STOC” (ID_FILM, COD_GEN_FILM, NUME_FILM, PRET_VHS, PRET_DVD, AN_APARITIE) VALUES (‘9’, ‘com’, ‘There is Something About Mary’, ’34’, ’17’, ‘2003’)
INSERT INTO “FILM”.”FILM_STOC” (ID_FILM, COD_GEN_FILM, NUME_FILM, PRET_VHS, PRET_DVD, AN_APARITIE) VALUES (’10’, ‘dra’, ‘Beloved’, ’30’, ’13’, ‘2002’)
INSERT INTO “FILM”.”FILM_STOC” (ID_FILM, COD_GEN_FILM, NUME_FILM, PRET_VHS, PRET_DVD, AN_APARITIE) VALUES (‘2’, ‘act’, ‘Under Siege’, ’28’, ’17’, ‘2000’)
INSERT INTO “FILM”.”FILM_STOC” (ID_FILM, COD_GEN_FILM, NUME_FILM, PRET_VHS, PRET_DVD, AN_APARITIE) VALUES (‘3’, ‘act’, ‘Lethal Weapon’, ’28’, ’19’, ‘2006’)
INSERT INTO “FILM”.”FILM_STOC” (ID_FILM, COD_GEN_FILM, NUME_FILM, PRET_VHS, PRET_DVD, AN_APARITIE) VALUES (‘7’, ‘thril’, ‘Frantic’, ’37’, ’20’, ‘2010’)Tabelul „FILM_STOC” din baza noastră de date „FILM” va avea structura în urma inserării datelor ca în figura 1.

Figura 1. Conţinut tabel Film Stoc
Pentru a introduce date în tabelul „GEN_FILM” utilizăm următorul cod SQL:
INSERT INTO “FILM”.”GEN_FILM” (COD_GEN_FILM, DESCRIERE_FILM) VALUES (‘act’, ‘actiune’)
INSERT INTO “FILM”.”GEN_FILM” (COD_GEN_FILM, DESCRIERE_FILM) VALUES (‘com’, ‘comedie’)
INSERT INTO “FILM”.”GEN_FILM” (COD_GEN_FILM, DESCRIERE_FILM) VALUES (‘dra’, ‘drama’)
INSERT INTO “FILM”.”GEN_FILM” (COD_GEN_FILM, DESCRIERE_FILM) VALUES (‘SF’, ‘stiintific’)
INSERT INTO “FILM”.”GEN_FILM” (COD_GEN_FILM, DESCRIERE_FILM) VALUES (‘cart’, ‘desene an.’)
INSERT INTO “FILM”.”GEN_FILM” (COD_GEN_FILM, DESCRIERE_FILM) VALUES (‘thril’, ‘triller’)Tabelul „GEN_FILM” va avea structura în urma inserării datelor ca în figura 2.
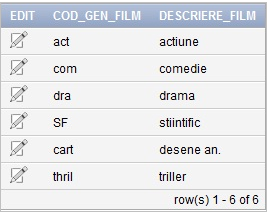
Figura 2. Conţinut tabel Gen Film
Pentru a introduce date în tabelui „LIMBA_FILM” utilizăm următorul cod SQL:
INSERT INTO “FILM”.”LIMBA_FILM” (ID_FILM, COD_LIMBA) VALUES (‘1’, ‘en’)
INSERT INTO “FILM”.”LIMBA_FILM” (ID_FILM, COD_LIMBA) VALUES (‘4’, ‘en’)
INSERT INTO “FILM”.”LIMBA_FILM” (ID_FILM, COD_LIMBA) VALUES (‘5’, ‘en’)
INSERT INTO “FILM”.”LIMBA_FILM” (ID_FILM, COD_LIMBA) VALUES (‘6’, ‘en’)
INSERT INTO “FILM”.”LIMBA_FILM” (ID_FILM, COD_LIMBA) VALUES (‘8’, ‘en’)
INSERT INTO “FILM”.”LIMBA_FILM” (ID_FILM, COD_LIMBA) VALUES (‘9’, ‘en’)
INSERT INTO “FILM”.”LIMBA_FILM” (ID_FILM, COD_LIMBA) VALUES (’10’, ‘en’)
INSERT INTO “FILM”.”LIMBA_FILM” (ID_FILM, COD_LIMBA) VALUES (‘2’, ‘en’)
INSERT INTO “FILM”.”LIMBA_FILM” (ID_FILM, COD_LIMBA) VALUES (‘3’, ‘en’)
INSERT INTO “FILM”.”LIMBA_FILM” (ID_FILM, COD_LIMBA) VALUES (‘7’, ‘en’)Tabelul “LIMBA_FILM” va avea structura în urma inserării datelor ca în figura 3.

Figura 3. Conţinut tabel Limba Film
Tabelui „SUBTITRARE” arată corespondenţa dintre limba originală a filmului şi limba în care este subtitrat. Pentru a introduce în tabel datele care arată această corespondenţă utilizăm următorul cod SQL:
INSERT INTO “FILM”.”SUBTITRARE” (COD_LIMBA, NUME_LIMBA) VALUES (‘en’, ‘romana’)Tabelul “SUBTITRARE” va avea structura în urma inserării datelor ca în figura 4.
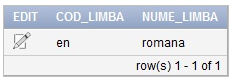
Figura 4. Conţinut tabel Subtitrare
Pentru a introduce date în tabelul „FILM_LIPSA_STOC” utilizăm următorul cod SQL:
INSERT INTO “FILM”.”FILM_LIPSA_STOC” (ID_LIPSA_FILM, FILM_DENUMIRE, FORMAT_SUPORT) VALUES (’23’, ‘Courage Under Fire’, ‘DVD’)
INSERT INTO “FILM”.”FILM_LIPSA_STOC” (ID_LIPSA_FILM, FILM_DENUMIRE, FORMAT_SUPORT) VALUES (’41’, ‘Die Hard a Vengeance’, ‘VHS’)
INSERT INTO “FILM”.”FILM_LIPSA_STOC” (ID_LIPSA_FILM, FILM_DENUMIRE, FORMAT_SUPORT) VALUES (’63’, ‘The Replacement Killers’, ‘DVD’)Tabelul “FILM_LIPSA_STOC” va avea structura în urma inserării datelor ca în figura 5.

Figura 5. Conţinut tabel Film Lipsa Stoc
Pentru a introduce date în tabelui „COPII_FILM” utilizăm urmatorul cod SQL:
INSERT INTO “FILM”.”COPII_FILM” (ID_FILM, NR_COPII, DENUMIRE_FILM, FORMAT_MEDIA) VALUES (‘3’, ‘4’, ‘Lethal Weapon’, ‘DVD’)
INSERT INTO “FILM”.”COPII_FILM” (ID_FILM, NR_COPII, DENUMIRE_FILM, FORMAT_MEDIA) VALUES (‘1’, ‘6’, ‘The Matrix’, ‘DVD’)
INSERT INTO “FILM”.”COPII_FILM” (ID_FILM, NR_COPII, DENUMIRE_FILM, FORMAT_MEDIA) VALUES (‘7’, ‘3’, ‘Frantic’, ‘DVD’)Tabelul “COPII_FILM” va avea structura în urma inserării datelor ca în figura 6 şi va conţine filmele care deţin copii.
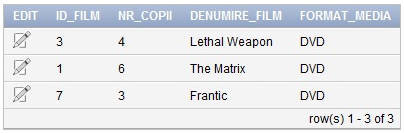
Figura 6. Conţinut tabel Copii Film
Pentru a introduce datele corespunzătoare filmelor pe care le-am închiriat în tabelul „FILME_INCHIRIATE”, utilizăm următorul cod SQL:
INSERT INTO “FILM”.”FILME_INCHIRIATE” (ID_FILM, ID_FILM_COPIE, DATA_INCHIRIERE, TITLU_FILM, PRET_INCHIRIERE) VALUES (‘3’, ‘2’, TO_DATE(’04-APR-06′, ‘DD-MON-RR’), ‘Lethal Weapon’, ’19’)
INSERT INTO “FILM”.”FILME_INCHIRIATE” (ID_FILM, ID_FILM_COPIE, DATA_INCHIRIERE, TITLU_FILM, PRET_INCHIRIERE) VALUES (‘1’, ‘3’, TO_DATE(’21-JUN-01′, ‘DD-MON-RR’), ‘The Matrix’, ’18’)
INSERT INTO “FILM”.”FILME_INCHIRIATE” (ID_FILM, ID_FILM_COPIE, DATA_INCHIRIERE, TITLU_FILM, PRET_INCHIRIERE) VALUES (‘7’, ‘3’, TO_DATE(’11-AUG-10′, ‘DD-MON-RR’), ‘Frantic’, ’20’)Tabelul “FILME_INCHIRIATE” va avea structura în urma inserării datelor ca în figura 7.
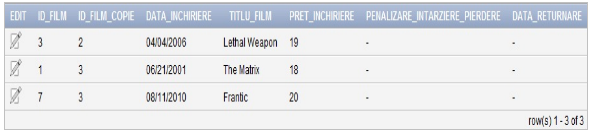
Figura 7. Conţinut tabel Filme Inchiriate
Pentru a introduce datele clienţilor care au închiriat filme de la magazinul nostru, în tabelul „CLIENTI_INCHIRIERE_FILM”, utilizăm următorul cod SQL:
INSERT INTO “FILM”.”CLIENTI_INCHIRIERE_FILM” (CLIENT_ID, NUME, PRENUME, ADRESA, ORAS, CNP, TEL) VALUES (‘2632’, ‘Popescu’, ‘Valentin’, ‘Republicii 22’, ‘Bucuresti’, ‘1426784951209’, ‘0214716683’)
INSERT INTO “FILM”.”CLIENTI_INCHIRIERE_FILM” (CLIENT_ID, NUME, PRENUME, ADRESA, ORAS, CNP, TEL) VALUES (‘1874’, ‘Ana’, ‘Maria’, ‘Take Ionescu 12’, ‘Timisoara’, ‘2705448793256’, ‘0256447391’)
INSERT INTO “FILM”.”CLIENTI_INCHIRIERE_FILM” (CLIENT_ID, NUME, PRENUME, ADRESA, ORAS, CNP, TEL) VALUES (‘4133’, ‘Alexandru’, ‘Nicolae’, ‘Soroca 36’, ‘Brasov’, ‘1203698754128’, ‘0729477596’)Tabelul “CLIENTI _INCHIRIERE_FILM” va avea structura în urma inserării datelor ca în figura 8 şi va conţine datele personale ale clienţilor care au inchiriat filme.
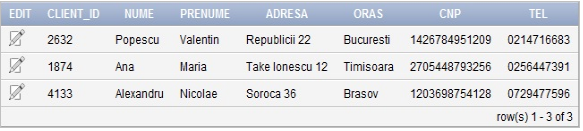
Figura 8. Conţinut tabel Clienti Inchiriere Film
Diagrama entitate – relaţie
Diagrama E/R pentru modelul de date prezentat se poate vedea în figura 12.
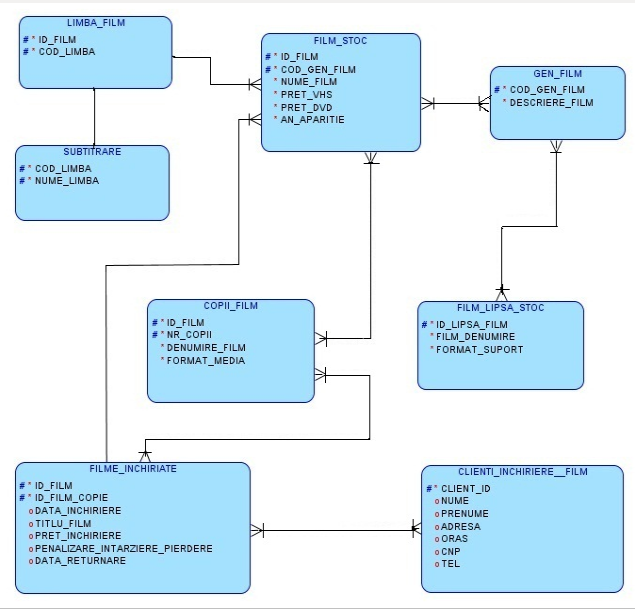
Fig.12. Diagrama E/R a studiului de caz
Pentru modelul de date pe care îl descriu entităţile sunt următoarele:
FILM_STOC, GEN_FILM, LIMBA_FILM, SUBTITRARE, FILM_LIPSA_STOC, COPII_FILM, FILME_INCHIRIATE, CLIENTI_INCHIRIERE_FILMAm să prezint în continuare entitaţile modelului de date al studiului de caz şi voi face o descriere a fiecareia. Voi preciza cheia primară pentru fiecare entitate.
FILM_STOC = conţine informaţii despre numele filmelor pe care le deţine în stoc societatea care are ca activitate închirierea de filme către clienţi. De asemenea tot aici găsim şi preţul de închiriere pentru aceste filme atât pe supart VHS cât şi pe DVD, anul apariţiei filmului şi un cod asociat filmului respectiv. Cheia primară a entitaţii este “id_film”.
GEN_FILM = oferă informaţii despre genul filmelor deţinute pe stoc. Cheia primară a entitaţii este “cod_gen_film”.
LIMBA_FILM = furnizează informaţii despre limba originală a filmelor existente pe stoc. Cheia primară a entitaţii este o cheia compusă din “id_film” şi “cod_limba”.
SUBTITRARE = ne spune limba în care sunt titrate filmele care au un anumit cod pentru limbă în entitatea LIMBA_FILM. Adica ce subtitrare îi corespunde unui anumit film care are un cod pentru limbă în entitatea LIMBA_FILM. Cheia primară a entitaţii este o cheie compusă din “ cod_limba” şi “nume_limba”
FILM_LIPSA_STOC = ne oferă informaţii despre filmele care nu sunt disponibile în stoc şi formatul acestora VHS sau DVD. Cheia primară a entitaţii este “id_lipsa_film”.
COPII_FILM = oferă informaţii despre nr. de copii existente ale filmelor din stoc, denumirea acestor filme căt şi suportul pe care se găsesc aceste filme VHS sau DVD. Cheia primară a entitaţii este o cheia compusă din “ id_film” şi “ nr_copii”.
FILME_INCHIRIATE = furnizează informaţii despre filmele închiriate clienţilor, titlul filmelor închiriate , pretul de închiriere, data închirierii, data cand filmele trebuie returnate cât şi penalizarea pentru întarzierea returnării sau pierderii produsului. Cheia primară a entitaţii este o cheie compusă din “id_film” şi “id_film_copie”.
CLIENTI_INCHIRIERE_FILM = ne oferă informaţii despre datele personale ale clienţilor care au inchiriat filme, cât şi numarul de telefon al acestora. Cheia primară a entitaţii este “client_id”.
Am să prezint relaţiile modelului de date al studiului de caz şi voi face o descriere a acestora. De asemenea pentru fiecare relaţie voi prezenta cardinalitatea minimă şi maximă.
FILM_STOC are GEN_FILM = relaţia dintre FILM_STOC şi GEN_FILM reflectă legătura dintre acestea ( un film existent pe stoc are un anumit gen, de ex. actiune, comedie, etc). Ea are cardinalitatea minima 1:1 (un film existent în stoc are un anumit gen şi un anumit gen de film poate să existe în filmele de pe stoc) şi cardinalitatea maximă 1:n ( un film existent în stoc are un anumit gen, dar mai multe genuri de filme pot exista pe stoc).
FILM_STOC închiriază FILME_INCHIRIATE = relaţia de tip many-to-many dintre entitatea FILM_STOC şi FILME_INCHIRIATE reflectă legatura dintre acestea ( unul sau mai multe filme de pe stoc sunt oferite spre a fi inchiriate ). Această relaţie are cardinalitatea 1:1 ( un anumit film existent în stoc este oferit spre a fi inchiriat şi de asemenea un film inchiriat este unul din filmele existente pe stoc) şi cardinalitatea maximă m:n ( mai multe filme existente pe stoc sunt oferite spre inchiriere şi mai multe filme închiriate sunt dintre filmele existente pe stoc).
FILM_STOC are COPII_FILM = relaţie de tip many-to-many dintre entitaţile FILM_STOC şi COPII_FILM arată legatura dintre acestea (mai multe filme existente pe stoc au mai multe copii ). Această relatie are cardinalitatea maximă m:n şi cardinalitatea minima 1:1.
FILM_STOC are LIMBA_FILM = relaţia dintre entitaţile FILM_STOC şi LIMBA_FILM reflectă legatura dintre aceste entitaţi ( unul sau mai multe filme de pe stoc au o limbă originală în care au fost regizate ). Aceasta relaţie are cardinalitatea minimă 1:1 ( un film de pe stoc are o limbă în care a fost regizat ) şi cardinalitatea maximă 1:n ( mai multe filme din stoc au o singură limbă în care au fost regizate ).
LIMBA_FILM are SUBTITRARE = relaţia dintre entităţile LIMBA_FILM şi SUBTITRARE ( limba originală în care a fost regizat un anumit film are o anumită subtitrare ). Relaţia are cardinalitatea minimă 1:1 (un film are o subtitrare şi o subtitrare corespunde unui film) şi cadinalitatea maximă 1:n (o subtitrare poate exista la mai multe filme).
CLIENTI_INCHIRIERE_FILM închiriază FILME_INCHIRIATE = relaţie de tip many-to-many dintre entitaţile CLIENTI_INCHIRIERE_FILM şi FILME_INCHIRIATE reflectă legătura dintre acestea ( filmele care sunt închiriate clientilor ). Această relaţie are cardinalitatea maximă m:n (mai multe filme sunt închiriate la mai mulţi clienţi şi mai multi clienti au inchiriat mai multe filme) şi cardinalitatea minimă 1:1 (un film este închiriat la un client şi un client a închiriat un singur film).
COPII_FILM închiriază FILME_INCHIRIATE = relaţie de tip many-to-many dintre entitaţiile COPII_FILM şi FILME_INCHIRIATE reflectă legătura dintre aceste entitaţi (copii a filmelor sunt închiriate). Această relaţie are cardinalitatea maximă m:n (mai multe copii ale filmelor sunt închiriate şi mai multe filme închiriate sunt dintre filmele care au copii).
FILM_LIPSA_STOC are GEN_FILM = relaţia dintre entitaţile FILM_LIPSA_STOC şi GEN_FILM reflectă legătura dintre acestea ( filmele care nu sunt disponibile pe stoc au anumite genuri ). Aceasta relaţie are cardinalitatea 1:1 ( un film inexistent pe stoc are un gen şi un anumit gen de film nu există printre filmele care nu sunt momentan disponibile pe stoc ), şi cardinalitatea maximă n:m.
În continuare am să descriu trei entitaţi împreună cu atributele acestora, tipurile de date, lungimea lor maximă şi o descriere a acestora pentru exemplificare.
id_film = variabilă de tip number, de lungime maximă 2, care reprezintă id-ul unui film existent pe stoc
code_gen_film = variabilă de tip varchar 2, de lungime maximă 8 biti, care reprezintă codul genului de film existent pe stoc
nume_film = variabilă de tip varchar 2, de lungime maximă 50 biti, care reprezintă numele filmului
pret_VHS = variabilă de tip float, de lungime maximă 2, care reprezintă preţul de închiriere a unui film pe suport VHS
pret_DVD = variabilă de tip float, de lungime maximă 2, care reprezintă preţul de închiriere a unui film pe suport DVD
an _aparitie = variabilă de tip number, de lungime maximă 4, care reprezintă anul de aparitie al filmului
Id_film = variabilă de tip number, de lungime maximă 2, care reprezintă id-ul filmului închiriat
Id_film_copie = variabilă de tip number, de lungime maximă 2, care reprezintă id-ul filmului copie şi împreuna cu id_film formerază cheia primară a entitaţii FILME_INCHIRIATE
Data_inchiriere = variabilă de tip date, care reprezintă data la care a fost închiriat un anumit film
Titlu_film = variabilă de tip varchar 2 , de lungime 50 biti, care reprezintă titlul filmului închiriat
Pret_inchiriere = variabilă de tip float, de lungime maximă 2, care reprezintă preţul închirierii filmului
Data_returnare = variabilă de tip date, care reprezintă data la care a fost returnat filmul închiriat
Client_id = variabilă de tip number, de lungime maximă 2, care reprezintă id-ul clientului care a închiriat un anumit film
Nume = variabilă de tip varchar 2, de lungime maximă 16 biti, care reprezintă numele clientului care a închiriat filme
Prenume = variabilă de tip varchar 2, de lungime maximă 16 biti, care reprezintă prenumele clientului care a închiriat filme
Adresa = variabilă de tip varchar 2 , de lungime 32 biti, care reprezintă adresa clientului care a închiriat filme
Oras = variabilă de tip varchar 2, de lungime maximă 16 biti, care reprezintă oraşul din care este clientul care a închiriat filme
Cnp = variabilă de tip varchar 2, de lungime maximă 13 biti, care reprezintă codul numeric personal al clientului
Tel = variabilă de tip varchar 2, de lungime maximă 16 biti, care reprezintă numarul de telefon al clientului
Voi descrie în continuare ca exemplu atributele relaţiei “FILM_STOC are GEN_FILM”, tipul de date, lungimea în biti a fiecarui atribut al relaţiei şi ce reprezintă fiecare.
Relaţia FILM_STOC are GEN_FILM are ca atribute :
cod_gen_film = variabilă de tip varchar 2, de lungime maximă 8 biti, care reprezintă codul genului de film. Atributul trebuie să corespundă la o valoare a cheii primare din tabelul (entitatea) GEN_FILM.
id_film = variabilă de tip number, de lungime maximă 2, care reprezintă id-ul unui film existent pe stoc. Atributul trebuie să corespundă la o valoare a cheii primare din tabelul (entitatea) FILM_STOC.
descriere_film = variabilă de tip varchar 2, de lungime maximă 50 biti, care oferă o scurtă descriere despre un anumit film. Atributul trebuie să corespundă la o valoare corespunzătoare a tipului de date din tabelul (entitatea) GEN_FILM.
nume_film = variabilă de tip varchar 2, de lungime maximă 50 biti, care reprezintă numele filmului. Atributul trebuie să corespundă la o valoare corespunzatoare a tipului de date din tabelul (entitatea) FILM_STOC.
pret_VHS = variabilă de tip float, de lungime maximă 2, care reprezintă pretul de închiriere a unui film pe suport VHS. Atributul trebuie să corespundă la o valoare corespunzătoare a tipului de date din tabelul (entitatea) FILM_STOC.
pret_DVD = variabilă de tip float, de lungime maximă 2, care reprezintă preţul de închiriere a unui film pe suport DVD. Atributul trebuie să corespundă la o valoare corespunzătoare a tipului de date din tabelul (entitatea) FILM_STOC.
an _aparitie = variabilă de tip number, de lungime maximă 4, care reprezintă anul de apariţie al filmului. Atributul trebuie să corespundă la o valoare corespunzatoare a tipului de date din tabelul (entitatea) FILM_STOC.
Diagrama conceptuală – cheia primară, cheia străină
Primul pas în proiectarea unei baze de date relaţionale este acela de a analiza situaţia reală pe care trebuie să o reprezentăm sau să o modelăm prin intermediul bazei noastre de date.
Cerinţele utilizatorilor în ce priveşte datele pe care trebuie să le stocăm şi administrăm
Cerinţele utilizatorilor în ce priveşte operaţiile care trebuie să fie efectuate cu aceste dateÎn cazul modelului relaţional din lucrarea mea, pentru a obţine schema conceptuală voi pleca de la o descriere mai detaliată a entitaţilor şi atributelor, a relaţiilor dintre aceste entitaţi şi condiţiile pe care acestea trebuie să le îndeplinească, deci voi pleca de la diagrama E/R a studiului de caz. Scopul este de a reprezenta entităţiile şi legăturile dintre entităţi prin intermediul unor relaţii sau tabele.
În diagrama conceptuală voi reprezenta prin simbolul “x” locul unde este plasată cheia externă, iar prin simbolul “x” voi arăta că respectiva cheie externă este conţinută în cheia primară.
Schema conceptuală a bazei de date corespunde unei descrieri de forma:
nume_entitate = {listă de atribute}
Cheile primare sunt atributele subliniate. Entitaţile şi atributele sunt apelate prin substantive, iar relaţiile dintre entitaţi sunt denumite prin verbe. În unele cazuri ordinea entitaţilor din relaţie este importanta şi atunci avem doua relaţii care se citesc de la stanga la dreapta şi invers de la dreapta la stanga, dar şi situaţii în care ordine nu conteaza. Numele date entitaţilor şi relaţiilor trebuie să fie unice, iar numele atributelor trebuie să fie unice numai la nivelul aceleiaşi entitaţi. Este de preferat pentru simplitatea referinţelor, ca numele atributelor care sunt chei primare să fie unice la nivelul bazei de date.
Entitaţile independente CLIENTI_INCHIRIERE_FILM, FILM_LIPSA_STOC devin tabele independente. Cheile primare ale celor doua entitaţi independente sunt:
CLIENTI_INCHIRIERE_FILM = {CLIENT_ID, NUME, PRENUME, ADRESA, ORAS, CNP, TEL};
FILM_LIPSA_STOC = {ID_LIPSA_FILM, FILM_DENUMIRE, FORMAT_SUPORT};
Entitaţiile dependente devin tabele dependente. Cheile primare ale celor trei entitaţi dependente sunt urmatoarele:
COPI_FILM = { ID_FILM, NR_COPII, DENUMIRE_FILM, FORMAT_MEDIA };
FILME_INCHIRIATE = {ID_FILM, ID_FILM_COPIE, DATA_INCHIRIERE, TITLU_FILM, PRET_INCHIRIERE, PENALIZARE_INTARZIERE_PIERDERE, DATA_RETURNARE };
GEN_FILM = {COD_GEN_FILM, DESCRIERE_FILM };
Subentitatea SUBTITRARE devine subtabel , avand cheia primară compusă din atributele COD_LIMBA şi NUME_LIMBARelaţiile de tip one-to-one şi one-to-many devin chei externe.
Relaţia LIMBA_FILM are SUBTITRARE devine cheie externă în tabelul LIMBA_FILM, iar cheia externă “cod_limba” din tabelul LIMBA_FILM este conţinută în cheia primară a tabelului LIMBA_FILM.
Relaţia FILM_STOC închiriaza FILME_INCHIRIATE devine cheie externă în tabelul FILME _INCHIRIATE
Relaţiile de tip many-to-many devin tabele asociative, având două chei externe “id_film” şi “cod_gen_film” pentru cele patru tabele asociate.
Relaţia CLIENTI_INCHIRIERE_FILM închiriază FILME _INCHIRIATE devine tabel asociativ (INCHIRIAZA).
Relaţia FILME_INCHIRIATE închiriază COPII_FILM devine tabel asociativ (INCHIRIAZA).
Relaţia FILM_LIPSA_STOC are GEN_FILM devine tabel asociativ (ARE).
Relaţia FILM_STOC are GEN_FILM devine tabel asociativ (ARE).
Relaţiile de tipul trei (cele care leagă cel putin trei entitaţi) devin tabele asociative, având chei externe pentru fiecare dintre tabelele asociate.
Relaţia ‘are” care leagă entităţile FILM_STOC, GEN_FILM, LIMBA_FILM, COPII_FILM devine tabel asociativ (ARE). Tabelul asociativ are chei externe atributele: ID_FILM şi COD_GEN_FILM , acestea sunt conţinute în cheile primare.
Schemele relaţionale corespunzătoare diagramei conceptuale sunt următoarele:
FILM_STOC(ID_FILM#, COD_GEN_FILM#, NUME_FILM, PRET_VHS, PRET_DVD, AN_APARITIE )
GEN_FILM(COD_GEN_FILM#, DESCRIERE_FILM )
LIMBA_FILM(ID_FILM#, COD_LIMBA# )
SUBTITRARE ( COD_LIMBA#, NUME_LIMBA# )
COPII_FILM ( ID_FILM#, NR_COPII#, DENUMIRE_FILM, FORMAT_MEDIA )
FILM_LIPSA_STOC ( ID_LIPSA_FILM#, FILM_DENUMIRE, FORMAT_MEDIA )
FILME_INCHIRIATE ( ID_FILM#, ID_FILM_COPIE#, DATA_INCHIRIERE, TITLU_FILM, PRET_INCHIRIERE, PENALIZARE_INTARZIERE_PIERDERE, DATA_RETURNARE )
CLIENTI_INCHIRIERE_FILM ( CLIENT_ID#, NUME, PRENUME, ADRESA, ORAS, CNP, TEL )Diagrama conceptuală a schemelor relaţionale mai sus menţionate se poate vedea în figura 13.
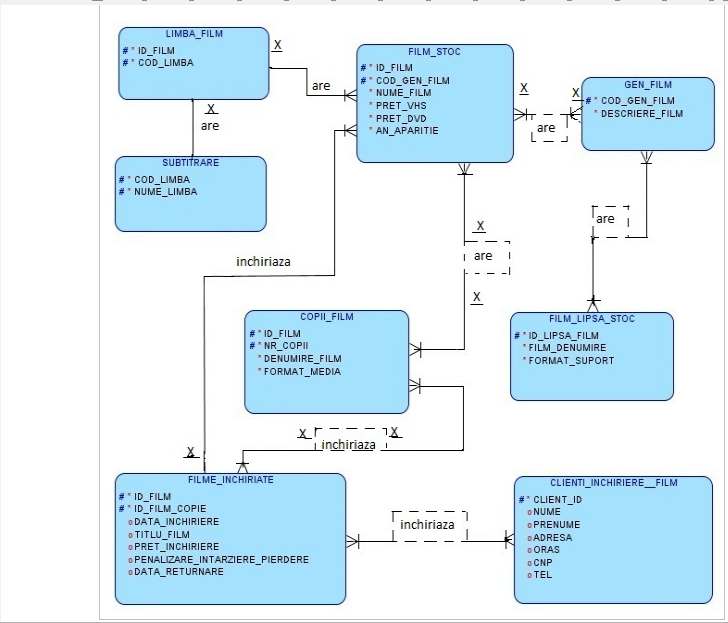
Fig.13. Diagrama conceptuală a studiului de caz
Interogări – exemple de interogări
Pentru a selecta toate filmele pe care le deţinem în baza de date folosim instrucţiunea SELECT în felul urmator:
SELECT * FROM FILM_STOC;Rezultatul aceste interogări se poate vedea în tabelul 14.
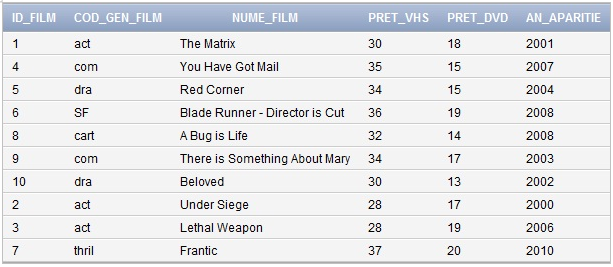
Fig.14. Conţinut tabel Film Stoc
Pentru a selecta doar un anumit film din baza noastră de date de ex. filmul “Under Siege” folosim instructiunea SELECT împreuna cu clauza WHERE în felul urmator:
SELECT * FROM FILM_STOC
WHERE NUME_FILM = ‘Under Siege’;Rezultatul acestei interogari va fi cel din figura 15.

Fig.15. Rezultat interogare folosind clauza WHERE
Pentru a vedea căte copii ale filmului “Lethal Weapon” avem utilizăm urmatoarea interogare:
SELECT * FROM COPII_FILM
WHERE DENUMIRE_FILM =’Lethal Weapon’
AND ID_FILM = ‘3’;Rezultatul acestei interogari va fi cel din fig. 16.

Fig.16. Rezultat interogare după nr. copii film Lethal Weapon
Pentru a interoga baza noastră de date şi a afla dacă filmul ‘Die Hard a Vengeance’ este unul din filmele care nu le detinem pe stoc la un moment dat, iar formatul suportului este VHS putem utiliza următoarea interogare:
SELECT * FROM FILM_LIPSA_STOC
WHERE FILM_DENUMIRE =’Die Hard a Vengeance’
AND FORMAT_SUPORT = ‘VHS’;Rezultatul interogarii este cel din fig. 17.

Fig.17. Rezultat interogare după film lipsa stoc şi suport VHS
Dacă dorim să interogam baza noastră de date pentru a afla informatii care sunt dispuse în două sau mai multe tabele putem utiliza instrucţiunea SELECT în combinaţie cu clauzele WHERE şi JOIN. De exemplu dacă dorim să aflăm denumirea filmelor care au copii, formatul media al acestor filme şi data la care aceste copii ale filmelor au fost închiriate clienţilor utilizăm clauzele WHERE şi JOIN în interogare în felul următor:
SELECT DENUMIRE_FILM, FORMAT_MEDIA, DATA_INCHIRIERE FROM COPII_FILM C, FILME_INCHIRIATE F WHERE C.ID_FILM = F.ID_FILM;
sau cu clauza join:SELECT DENUMIRE_FILM, FORMAT_MEDIA, DATA_INCHIRIERE FROM COPII_FILM C JOIN FILME_INCHIRIATE F ON (C.ID_FILM=F.ID_FILM);
sau în felul urmator:SELECT DENUMIRE_FILM, FORMAT_MEDIA, DATA_INCHIRIERE FROM COPII_FILM JOIN FILME_INCHIRIATE USING (ID_FILM);
Rezultatul acestor trei metode de interogări va fi cel din fig.18
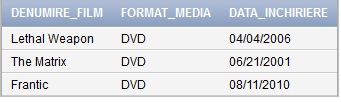
Fig.18. Rezultatul interogărilor întoarce date din două tabele
Selecţia de mai jos cu clauza JOIN extrage date din tabelele FILM_STOC şi LIMBA_FILM şi ne oferă informaţii despre numele filmului, anul apariţiei şi limba în care a fost regizat filmul.
SELECT NUME_FILM, AN_APARITIE, COD_LIMBA
FROM FILM_STOC F JOIN LIMBA_FILM L ON (F.ID_FILM = L.ID_FILM);Rezultatul interogarii este arătat în figura 19.
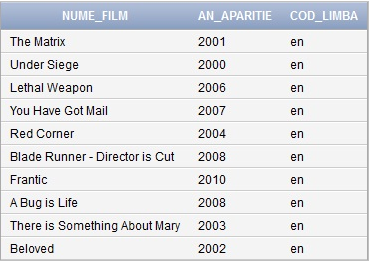
Fig.19. Rezultatul interogării întoarce date din tabelul FILM_STOC şi LIMBA_FILM
Daca dorim să aflăm o scurtă descriere a fiecarui film din figura 19 putem utiliza următoarea interogare folosind clauza JOIN în felul urmator:
SELECT NUME_FILM, DESCRIERE_FILM
FROM FILM_STOC F JOIN GEN_FILM G ON (F.COD_GEN_FILM = G.COD_GEN_FILM);sau în felul urmator:
SELECT NUME_FILM, DESCRIERE_FILM
FROM FILM_STOC JOIN GEN_FILM USING (COD_GEN_FILM);Rezultatul celor două modalităţi de interogare va fi cel din figura 20.
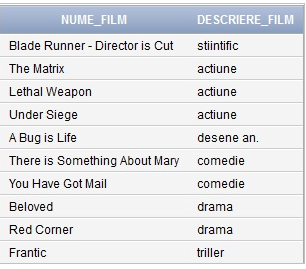
Fig. 20. Rezultatul celor două interogării oferă o scurtă descriere a fiecărui film din fig 19
Daca dorim să ţinem evidenţa tuturor filmelor de acţiune care au fost închiriate într-o perioadă de timp, numele şi prenumele celor care au închiriat aceste filme, cât şi data închirierii şi preţul avem nevoie să consultăm informaţii care se află în trei tabele şi anume FILM_STOC, CLIENTI_INCHIRIERE_FILM, FILME_INCHIRIATE. Pentru a obţine aceste informaţii putem crea o vizualizare şi apoi să consultăm acea vizualizare ca să obţinem informaţiile care ne interesează.
Vizualizarea pe care am creat-o ca exemplu se numeste FILME_ACT_INCHIRIATE şi are urmatorul cod SQL:
CREATE VIEW FILME_ACT_INCHIRIATE AS
SELECT COD_GEN_FILM, NUME_FILM, NUME, PRENUME, DATA_INCHIRIERE, PRET_INCHIRIERE
FROM FILM_STOC, CLIENTI_INCHIRIERE_FILM, FILME_INCHIRIATE
WHERE COD_GEN_FILM = ‘act’ ;Acum putem consulta vizualizarea creată şi deci obţine informaţiile care ne interesează. Pentru a face acest lucru folosim urmatoarea interogare:
SELECT * FROM FILME_ACT_INCHIRIATE;Rezultatul acestei selecţii va afişa vizualizarea creată anterior, vezi fig.21
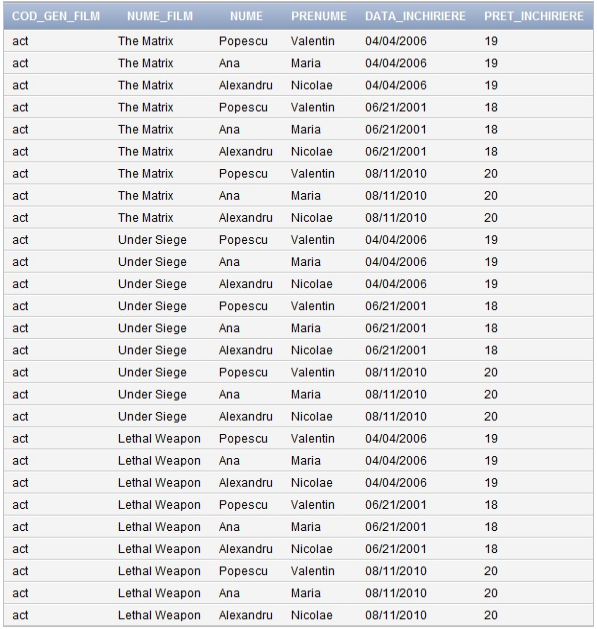
Fig.21. Vizualizare FILME_ACT_INCHIRIATE
Putem căuta în vizualizarea noastră doar informaţiile care ne interesează, de exemplu dorim să ştim ce filme a închiriat un anumit client şi anume Popescu Valentin. Pentru a obţine doar acele linii din vizualizarea noastră care corespund clientului Popescu Valentin, rafinăm căutatea noastră adăugând clauza WHERE în interogare ca în exemplul de mai jos:
SELECT * FROM FILME_ACT_INCHIRIATE
WHERE NUME = ‘Popescu’ AND PRENUME = ‘Valentin’;Acum rezultatul selecţiei din vizualizarea noastră va întoarce doar înregistrarile care corespund clientului Popescu Valentin. În figura 22 putem vedea doar înregistrarile referitoare la clientul Popescu Valentin.
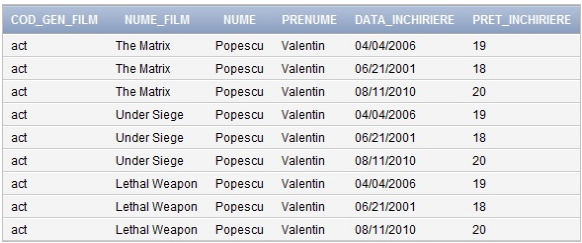
Fig.22. Vizualizare FILME_ACT_INCHIRIATE care corespunde clientului Popescu Valentin
наркологический вывод из запоя наркологический вывод из запоя
вызвать капельницу от запоя вызвать капельницу от запоя